Měření spotřebovaného času procesoru v Linuxu
16.3.2019
Ukážeme si jak v Linuxu zjistit spotřebovaný čas procesoru jak pro proces, tak pro jeho jednotlivá vlákna.
Měření časového intervalu s vysokou přesností
Pro měření časového intervalu v Linuxu použijeme funkci clock_gettime, která naplní 2. parametr (struktura timespec) časovým údajem s přesností až na nanosekundy. Reálnou přesnost lze v případě potřeby zjistit funkcí clock_getres. Časový údaj může být buď čas od začátku periody, nebo čas procesoru (CPU) který proces nebo thread spotřeboval. O jaký čas se bude jednat určíme v 1. parametru funkce příslušnou hodnotou, která je pro změření reálného času CLOCK_REALTIME, pro čas CPU procesu CLOCK_PROCESS_CPUTIME_ID a pro čas CPU vlákna CLOCK_THREAD_CPUTIME_ID. Nejprve si tedy vytvoříme pomocné třídy pro měření jednotlivých typů času:
// pro změření obecného časového intervalu
class Cas
{
protected:
timespec ts_start;
timespec ts_stop;
clockid_t typ = CLOCK_REALTIME;
public:
void start() noexcept
{
clock_gettime(this->typ, &this->ts_start);
}
void stop() noexcept
{
clock_gettime(this->typ, &this->ts_stop);
}
double interval() noexcept
{
return ts_stop.tv_sec - ts_start.tv_sec +
(ts_stop.tv_nsec - ts_start.tv_nsec) / 1000000000.;
}
};
// pro změření spotřebovaného procesorového času celého procesu
class CasCpuProcess : public Cas
{
public:
CasCpuProcess() noexcept
{
this->typ = CLOCK_PROCESS_CPUTIME_ID;
}
};
// pro změření spotřebovaného procesorového času jedntlivého vlákna
class CasCpuThread : public Cas
{
public:
CasCpuThread() noexcept
{
this->typ = CLOCK_THREAD_CPUTIME_ID;
}
};
Nyní si vytvoříme nějaký testovací kód ve kterém zaměstnáme procesor a který zavoláme v pararelních vláknech. Pro spuštění vláken využijeme standardní knihovnu C++ a její třídu std::thread. V prováděcí funkci vlákna budeme v cyklu volat funkci na zjištění, zda jejím vstup je prvočíslo a pro každé vlákno změříme procesorový čas vlákna a celkový čas provádění této funkce. Aby bylo odlišení těchto časů výraznější, přidáme volání funkce sleep, který nespotřebuje čas procesoru ale zvýší celkový naměřený čas.
bool je_prvocislo(unsigned int cislo) noexcept
{
unsigned int mez = (unsigned int)sqrt(cislo);
for (unsigned int i = 2; i <= mez; i++)
{
if (0 == cislo % i)
return false;
}
return true;
}
void funkce_thread(size_t pocet, int vlakno) noexcept
{
Cas cas;
CasCpuThread cas_thread;
cas.start();
cas_thread.start();
unsigned int pocet_prv = 0;
for (size_t i = 0; i < pocet; i++)
{
if (je_prvocislo(i))
pocet_prv++;
}
sleep(2); // 2 sekundy které nezaměstnají procesor
cas_thread.stop();
cas.stop();
printf("thread: %d, čas: %.6f, čas cpu thread: %.6f (počet: %d)\n",
vlakno, cas.interval(), cas_thread.interval(), (int)pocet_prv);
}
Nyní zbývá vytvořit 4 pararelně běžící vlákna a změřit celkový čas za který budou všechna ukončena a zjistit celkový spotřebovaný procesorový čas.
int main(int argc, const char** argv)
{
#define POCET_T 4
std::thread* threads[POCET_T];
Cas cas;
CasCpuProcess cas_process;
cas.start();
cas_process.start();
for (size_t i = 0; i < POCET_T; i++)
{
threads[i] = new std::thread(funkce_thread, 10000000, i);
}
for (size_t i = 0; i < POCET_T; i++)
{
threads[i]->join();
}
for (size_t i = 0; i < POCET_T; i++)
{
delete threads[i];
}
cas.stop();
cas_process.stop();
printf("čas celkem: %.6f, čas cpu procesu: %.6f\n",
cas.interval(), cas_process.interval());
printf("----------\nhotovo\n");
return EXIT_SUCCESS;
}
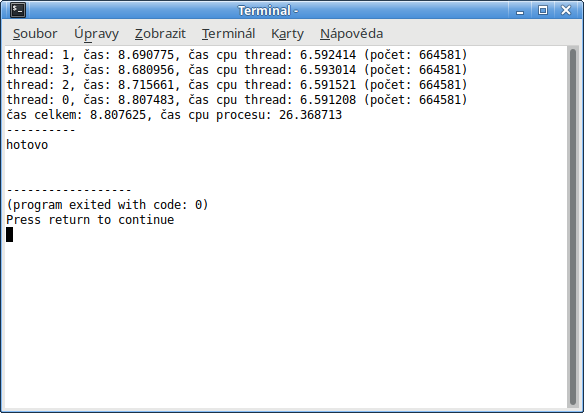
Jak je zřejmé z následujícího obrázku, při 4 vláknech na 4-jádrovém procesoru je celkový procesorový čas skoro 4-krát větší než absolutní čas potřebný na celý (pararelní) běh všech vláken (do kterého je započten čas pro funkci sleep(2)).
Školení
Kontakt
739 219 991
live:radekchalupa_1
Nové články